Transformer为什么这么火?毫末智行工程师一文揭秘
2021-09-02 16:34:30 来源:
作为在自然语言处理(NLP)领域应用广泛的深度学习模型,Transformer 近两年强势来袭,不仅横扫 NLP 领域,而且在 CV 上也锋芒毕露。江湖传言,Transformer 架构就像是绝世高手的武林秘籍,得秘籍者得天下!
毫末智行作为国内首先大规模使用 Vision Transformer 技术的公司,正在练就独门绝学,力求在智能驾驶的赛道上抢占先机。
Transformer 的杀手锏
我们知道,最初的 Transformer 来自于 NLP,它的出现将 NLP 领域向前推动了一大步。其中的关键要素就是Transformer 具备:超强的序列建模能力、全局信息感知能力。
得益于这两点优势,Transformer 几乎取代了基于 RNN 的算法在 NLP 中的地位,也被引入到 CV 领域。但值得我们深入思考的是,Transformer 如何利用优势在视觉领域发挥作用呢?
我们知道 NLP 中处理的是语句,句子是天然的序列数据,所以我们很容易理解 Transformer 是如何处理它们的。可在视觉领域,序列的概念并不是显式的,因此我们可以从空间和时间两个维度去理解。
首先是空间维度,静态图像从空间上可以被划分成多个区域(block),一种典型的划分方式就是按照高和宽进行划分,例如,一幅图像的高和宽分别是 H 和 W,我们要求 block 的长宽均为 M,那么最终我们会得到 (H/M ×;W/M) 个 block。
事实上,我们可以把 block 看成是 NLP 句子中的词,这里的只不过是视觉词(visual words)。这样一来,就可以将一幅图像转化成一个按照空间顺序排列的 block 集合,一方面这样的视角转换保证了不丢失视觉信息,另一方面让应用 Transformer 变得非常容易。
另一种则是通过时间维度去理解视觉中的序列,即视频。视频是由静态的图像帧组成,把每一帧看成是一个基本单元(同样可以类别成句子中的词),那么我们就可以很自然地按照时间序列把一个片段组织起来,从而应用 Transformer 进行后续的特征提取。
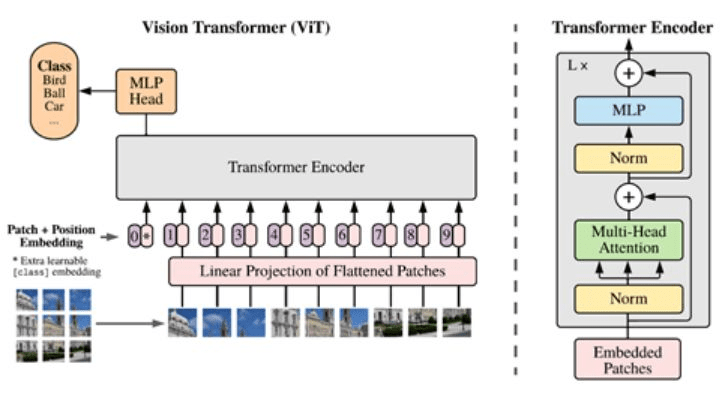
图引自论文《An Image is Worth 16x16 Words Transformer for Image Recognition at scale》
除了强大的序列建模能力,Transformer 的主要模块 Multi-Head Self-Attention 可以同时感知到输入序列的全局信息,这是 Transformer 相比于 CNN 的巨大优势。在 CNN 中,信息只能从局部开始,随着层数的增加,能够被感知到的区域逐步增大。然而Transformer 从输入开始,每一层结构都可以看到所有的信息,并且建立基本单元之间的关联,也意味着Transformer 能够处理更加复杂的问题。
Transformer 的优化升级
目前处于 Transformer 在视觉中应用的早期,大家使用 Transformer 的方式主要参考了其在 NLP 中的应用经验。但是,如果直接将 Transformer 应用到视觉上,也会存在一些难题。
其一,核心模块多头注意力机制(Multi-Head Self-Attention )的计算量与 block 的个数成正比,因此在视觉中 block 数量要远多于 NLP 中句子的词数,这就造成了计算量的陡增。
其二,Transformer 擅长全局关系的学习,对于局部细节信息关注有限,然而视觉中很多任务需要足够丰富的细节信息做判断,比如语义分割。
针对上述的问题,毫末智行人工智能研发团队对核心模块多头注意力机制(Multi-Head Self-Attention)进行了优化,同时采用了金字塔的结构增强 Transformer 对于细节信息的感知。
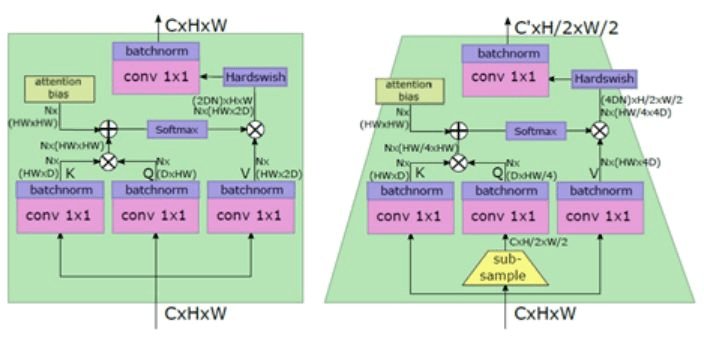
图引自论文《LeViT a Vision Transformer in ConvNet Clothing for Faster Inference》
Transformer 的未来演化
尽管我们在上面提到了 Transformer 的一些不尽如意之处,但随着研究的深入,大家逐步发现在同一结构中结合 CNN 和 Transformer 各自的优势,即可做到相互的扬长避短。在未来,把CNN 和 Transformer 进行整合将成为 Transformer 的演化路径之一。
具体来说,主干网使用 CNN,Head 使用 Transformer 结构,可以有效提升网络的速度(相比纯使用 Transformer);相反,主干网使用 Transformer 结构,Head 使用 CNN 的结构,可以有效提升结果精度(相比于纯使用 CNN)。
其次,核心模块 Multi-Head Self-Attention 内部也可以通过降低子空间的维度、对输入 block 进行分组等手段降低其计算量且不至于损失过多精度。
最后,通过控制 block 的粒度,使 Transformer 能够感知到不同尺度的信息,从而达到局部和全局的信息融合。
毫末智行团队已经将上述的改进逐步添加到了毫末智行自己的模型中。未来,我们将不断在提升速度的同时保证出色的精度,让 Transformer 在实际的业务中生根发芽。

图引自论文《End to End Object Detection with Transformers》
基于 Transformer 的感知算法表现出了极强的泛化性和鲁棒性,我们坚定认为,Transformer 的特性极有可能在智能驾驶的场景中发挥出传统 CNN 算法所不能企及的感知能力。
鉴于此,毫末智行的人工智能团队正在逐步将基于 Transformer 的感知算法应用到实际的道路感知问题,例如车道线检测、障碍物检测、可行驶区域分割、红绿灯检测识别、道路交通标志检测、点云检测分割等。 未来,相关 Transformer 感知算法更加和稳定成熟后,逐步替换基于 CNN 的感知算法。
Transformer 技术的进一步应用,不仅为毫末智行在各条智能驾驶产品线上的视觉算法落地带来成倍的效率提升,还能够让各项视觉性能指标快速达到业内水平。
-
Transformer为什么这么火?毫末智行工程师一文揭秘
作为在自然语言处理(NLP)领域应用广泛的深度学习模型,Transformer 近两年强势来袭,不仅横扫 NLP 领域,而且在 CV 上也锋芒毕露。江
2021-09-02 16:34
-

三星今年美国发明专利数将超越IBM
北京时间12月15日上午消息,三星今年很可能将超过IBM,成为获得美国发明专利数量最多的公司。 过去22年中,IBM一直是获得美国发明专利
2021-09-02 15:04
-
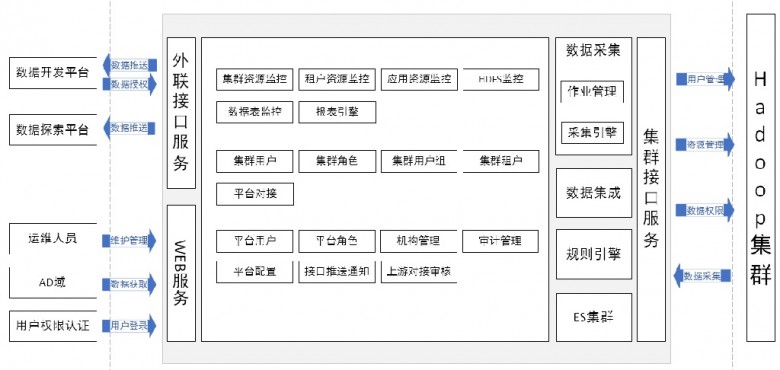
银兴智能:助力广发银行打造Hadoop资源管理平台
据深圳银兴智能数据有限公司(简称:银兴智能)介绍,随着广发银行大数据平台hadoop集群应用场景越来越多,研发中心、数据中心、卡中心和分
2021-09-02 10:41
-

搭载Viband技术一数科技Cast化身智能管家
在科技与需求的双重驱动下,人机交互形式逐渐从多点触控开始向体感技术发展,作为可以直接佩戴在身上参与人机交互的智能穿戴设备,智能
2021-09-02 09:37
-

爱普生智能光学模组VM-40赋能行业应用落地
7月8日至10日,2021世界人工智能大会在上海世博展览馆召开,全球行业精英齐聚一堂,围绕AI赋能城市数字化转型主题,勾画人工智能技术创新
2021-09-02 04:22
-

它来了!MoChat开源了一款超好用的企业微信开源SCRM系统,太香了
大家都知道,企业微信是腾讯旗下一款非常好用的、免年费的私域用户运营工具,但可惜的是企业微信只提供基础的能力,基于场景更丰富的功
2021-09-01 23:51